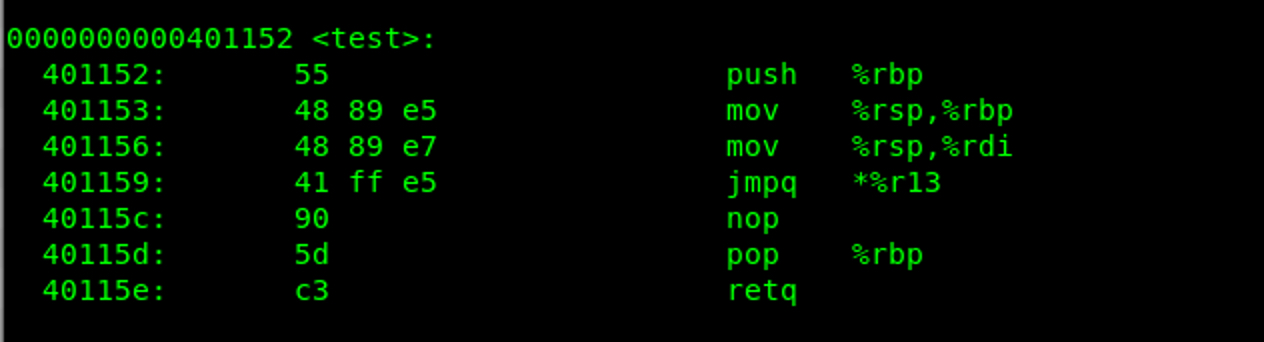
Threat hunting is the use case for EDR
(Nate Fick, CEO Endgame.)
Более чем 3 года назад, в 2016, мы впервые заговорили о Threat hunting на русском языке, позже появились и другие публикации, сейчас об этом говорят уже все, а прошлые SOC-и называют поставщиками сервисов MDR. Уже ни для кого не новость MITRE ATT&CK и многие производители, пытающиеся систематически подходить к тому самому Threat hunting, (далее - "активный поиск угроз" или "хантинг") уже прошли тест, и многие еще пройдут.
Однако, несмотря на эпиграф к этой статье и достаточно хорошее покрытие задачи со стороны EPP-EDR, надо все же стремиться к более комплексной истории, и заниматься активным поиском угроз не только на эндпоинте, но и на сети, о чем и поговорим в этой заметке.
Почему активный поиск угроз на сети важен? На слайде 27 я приводил тактики, с указанием эффективности сенсоров. Нетрудно сообразить, что сетевой активный поиск угроз будет здорово работать на:
и абсолютно незаменим на:
Более того, с точки зрения результативности, разумным подходом является использование принципа "кругового детекта", когда одна угроза обкладывается множеством различных детектирующих логик, работающих по разным принципам, таким образом, выпустив множество детектов - по сэмплу, по поведению, по похожести, по сетевому трафику и т.п. - мы увеличиваем вероятность успешного обнаружения (или предотвращения, если это технически возможно). Поэтому наличие сетевых IoA, как технологически абсолютно иных в сравнение с хостовыми IoA, в значительной степени повысят совокупный detection rate.
Если совсем кратко, то реализованные ранее EDR-ные подходы могут быть полностью перенесены на сеть: нам также нужен инструмент, поставляющий телеметрию, которую мы могли бы предварительно обогащать доступным ThreatIntel-ом, и поверх которой мы смогли бы делать TTP-based детекты, именуемые нами внутри "хантами" или публично индикаторами атаки (IoA). Некоторые примеры EDR-ной телеметрии приведены на слайде 9, а на слайде 11 приведен укрупненный пайплайн ее обработки: обогащение, далее - TTP-based разметка "хантами"\IoA, далее можно еще покоррелировать и поразмечать, в завершении - валидация живым аналитиком (или машиннообучаемым Автоаналитиком, может, как-нибудь напишу об этом). Приведу здесь картинку из презентации, которую показывал на одном из мероприятий:

В качестве сенсора для сетевого активного поиска угроз прекрасно подходит Network Forensics Tools. NFT - старый термин, стары и инструменты, но, если упрощенно определить активный поиск угроз - это форенсика, реализованная как операционный процесс, сейчас, находясь на этапе, когда атаки нельзя не только предотвратить, но даже и обнаружить полностью автоматически, активный поиск угроз - все что нам остается. При этом, на сети работают все те же подходы: пытаемся предотвратить (NGFW, IPS), не получилось - хотя бы обнаружить (IDS), не получилось и обнаружить автоматически - должна быть телеметрия для ручного хантинга. И здесь как раз нам поможет NFT.
Приведу пример на Bro/Zeek. Телеметрией для активного поиска угроз служат его логи, которые полностью расширяемые как по полям (примером может служить hassh от ребят из Salesforce), так и по типам логов - ничего не мешает написать парсер под любой загадочный протокол, журналлируемый в отдельный лог. Логи Zeek являются прекрасным компромиссом между сбором всего трафика, и сбором только детектов NGFW/IDS/IPS, но, вместе с тем, достаточным для сетевого хантинга. В этом плане их допустимо сравнить с сырыми нотификациями EDR, например, от sysmon.
Сырые логи Zeek можно также собрать в ELK, например так (правда, я бы сделал проще: настроил бы логгирование Bro в JSON, и тогда filter в конфиге Logstash был бы тривиален:
if "brologs" in [tags] {
json {
source => "message"
remove_field => "message"
}
}
), а уже запросами в Kibana удобно хантить.
Поверх телеметрии Zeek можно уже класть "ханты", автоматизирующие запросы к Elastic-у, аналогично как это делается у нас для телеметрии EPP-EDR. Для понимания приведу примеры хантов на телеметрии Zeek:
- прохождение неизвестного трафика через стандартный порт (техника - T1436)
- использование подозрительных методов RPC (T1175)
- подозрительный User-Agent - Mozilla/5.0 (Windows NT 10.0; Microsoft Windows 10.0.15063; en-US) PowerShell/6.0.0 (T1089)
Или что-нибудь более продвинутое, может даже с машобучем :)
Будучи немного погруженным в инжениринг детектов EDR могу поделиться проблемой, что далеко не любую телеметрию можно достать по причинам стабильности и производительности, а полагаться полностью на ETW не кажется надежным. В случае NFT таких проблем нет, поскольку трафик собирается пассивно, и анализируется не на целевой системе, и, следовательно, не влияет на ее производительность (плата за это очевидна - меньшая visibility, но, вместе с тем, - NFT непереоценимое дополнение к EPP-EDR)
Будучи немного погруженным в инжениринг детектов EDR могу поделиться проблемой, что далеко не любую телеметрию можно достать по причинам стабильности и производительности, а полагаться полностью на ETW не кажется надежным. В случае NFT таких проблем нет, поскольку трафик собирается пассивно, и анализируется не на целевой системе, и, следовательно, не влияет на ее производительность (плата за это очевидна - меньшая visibility, но, вместе с тем, - NFT непереоценимое дополнение к EPP-EDR)
Думаю, что уже очевидна полная аналогия, но все же приведу табличку:
| Перспектива | EPP-EDR | NFT |
|---|---|---|
| Prevent - Detect - Hunt | EPP - EDR - активный поиск угроз по телеметрии | NGFW/IPS - IDS - активный поиск угроз по телеметрии |
| Телеметрия | запуск процессов, загрузка библиотек, детект EPP, событие ОС, создание файла, инжект, ... | логи соединений, обнаруженное в сети ПО, пролетающие по сети файлы, логи протоколов прикладного уровня, ... |
| Ханты\Детекторы\IoA | Релевантные телеметрии | |
Важно понимать, что ни EDR, ни NFT не являются "серебряной пулей" по отдельности, важна именно комбинация методов, реализованная в виде единого интегрированного решения, где ханты EDR и NFT коррелируются и взаимно обогащают друг друга, предоставляя аналитику SOC максимальные возможности по хантингу.
В заключении хочется дополнить слова мистера Фика, указанные в эпиграфе: "Threat hunting is the use case for combination of EDR and NFT", что надеюсь, мне удалось доказать в этой заметке на примере Zeek.
Некоторые, возможно полезные, ссылки
- Zeek packages
- Perched ROCK NSM
- SecurityOnion
- HILTI & Spicy
- BZAR (Bro/Zeek ATT&CK-based Analytics and Reporting)
- Integrating Bro IDS with the Elastic Stack